Page 1 of 2
遇到一难题!
Posted: Apr 02 2010, 09:53
by liumailong
先上图

- 2010-04-02_09_32_32_000.png (20.67 KiB) Viewed 28374 times
这个标示的目标是
起点中文阅读页的一个链接,他其时也不怎么讨厌,但本身特殊:其既不在页面原始源代码中,也不js脚本中!而在小说的文本中。
有什么办法过滤它吗?
Re: 遇到一难题!
Posted: Apr 02 2010, 11:17
by ddbb
http://download.qidian.com/pda/1412902.txt
看到内容了吧
<a href=http://www.qidian.com>起点中文网www.qidian.com欢迎广大书友光临阅读,最新、最快、最火的连载作品尽在起点原创!</a>
然后就和过滤正常页面一样了.....
Code: Select all
[Patterns]
Name = "ad"
Active = FALSE
URL = "download.qidian.com/pda/1412902.txt"
Limit = 150
Match = "<a href=http://www.qidian.com>"
Replace = "<a href=http://111111111>"
Re: 遇到一难题!
Posted: Apr 02 2010, 15:16
by liumailong
http://download.qidian.com/pda/1412902.txt
是下载链接,不是阅读页的内容。
这个才是:
http://files.qidian.com/Author7/1412902/27140788.txt
不过我还是无法过滤
Code: Select all
Name = "Qidian 起点中文 阅读页 文本内广告"
Active = TRUE
URL = "*"
Limit = 22256
Match = "<a*www.qidian.com>*</a>"
PS:坛子是不是该升级了,我想重新编辑一下主题都不行
Re: 遇到一难题!
Posted: Apr 02 2010, 21:26
by Bonnie
这种我觉得用css隐藏比较方便。
Code: Select all
div#content>*:nth-last-child(-n+2)
Re: 遇到一难题!
Posted: May 10 2010, 11:25
by imsheng
用CSS定义是比较省资源的。替换和删除都比较费资源。
不过像你这个例子,这个txt文件,prox是不是没有过滤?
Re: 遇到一难题!
Posted: May 10 2010, 11:38
by ddbb
我用了你给出的那个规则后 是能过滤掉的 你要清一下缓存.....JS文件一般浏览器都是不读第2次的 如果有变更 不会被发现......
Re: 遇到一难题!
Posted: Jan 15 2011, 15:51
by 不夜侯
一楼所给出的起点这个链接,我也过滤不了
具体应该是在这个脚本中:
http://files.qidian.com/Author7/1412902/27140788.txt
Code: Select all
<script src='http://files.qidian.com/Author7/1412902/27140788.txt'></script>
下面规则测试通过,但实际是无效的。反复折腾也是如此。
Code: Select all
[Patterns]
Name = "ad"
Active = TRUE
URL = "files.qidian.com/"
Bounds = "<a\s*</a>"
Limit = 200
Match = "*www.qidian.com*"
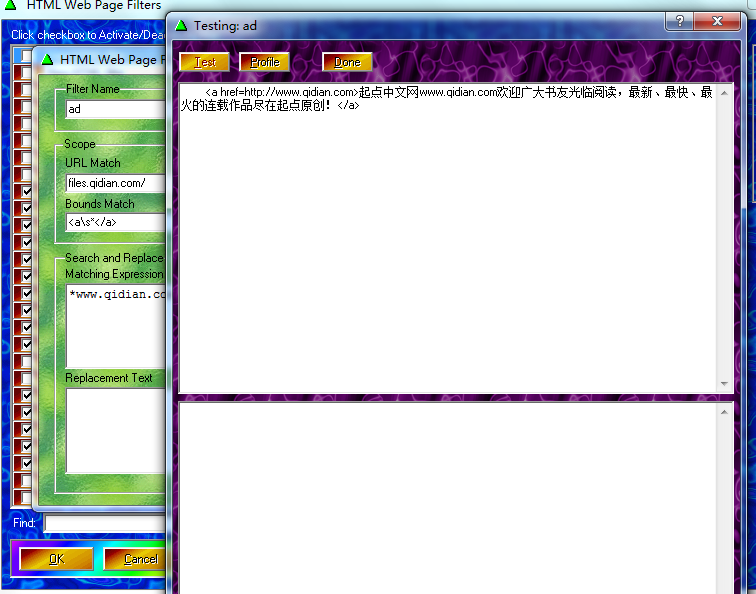
- 2011-01-15_154701.png (201.64 KiB) Viewed 28020 times
Re: 遇到一难题!
Posted: Jan 15 2011, 19:37
by dudu8995
试试这个:
Code: Select all
[Patterns]
Name = "Qidian"
Active = TRUE
URL = "$TYPE(js)files.qidian.com/"
Bounds = "$NEST(<a*>,</a>)"
Limit = 256
Match = "*www.qidian.com*"
Replace = "<!-- ProxO Kill AD -->"
Re: 遇到一难题!
Posted: Feb 17 2011, 01:35
by cre
看这里
http://forum.proxcn.info/viewtopic.php?f=2&t=192#p1050
webpages
Code: Select all
[Patterns]
Name = "qd del text"
Active = TRUE
URL = "$TYPE(oth)files.qidian.com"
Bounds = "<a\s*</a>"
Limit = 200
Match = "*www.qidian.com*"
header
Code: Select all
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: plain $FILTER(True) [in]"
URL = "files.qidian.com/\w.txt"
Match = "text/plain$FILTER(True)Proxoff"
楼上使用type(js)是不行的。
Re: 遇到一难题!
Posted: Feb 20 2011, 15:04
by dudu8995
由 cre 周四 2月 17, 2011 1:35 am
楼上使用type(js)是不行的。
我测试没有问题。
请有空闲的同学帮助测试和反馈一下。